对于Policy improvement作者没有给出严格的数学证明,其实至少从下面的角度可以严格证明Policy improvement的可行性。
从期望的一个性质说起
首先证明期望的一个性质:
至少存在一个随机变量,其值不小于随机变量的期望
证明如下:(参见《概率论基础教程》P251)
设为定义在有限集上的函数,假定我们对该函数的最大值感兴趣:
为得到的下界,令为取值于的随机元,显然有:,即:
即:
也就是说,函数的最大值不小于的期望,即在有限集上,一定存在值(最大值)不小于的期望。
状态价值函数和动作价值函数的关系
有了以上的结论,我们考察和的关系:
即在策略下,状态的价值为的期望,因此一定存在至少一个的最大值使得。亦即,在动作的集合中,一定存在至少一个动作,其不小于状态的价值。此结论对于任意都成立。
我们定义对于任意使得取最大值的策略为,其动作为,即:
于是有:
policy improvement可行性证明
利用上面的结论(公式),我们可以证明:
即greedy policy是policy improvement的可行策略。
证明如下:
上面的证明中,值得注意以下步骤:
-
2-2是的展开。
-
2-3是2-2的等价变化,意为在策略下的条件期望。进行这样的变换是为了方便后面推导出,因为状态价值函数是以状态为条件对策略的期望。
-
2-4根据公式将替换为。
-
2-5是的展开。
-
2-6是使用了期望的加法规则和“期望的期望是其本身”这个期望的性质,有必要单独拿出来说一下。
具体来说,2-6的推导过程可参见下图:
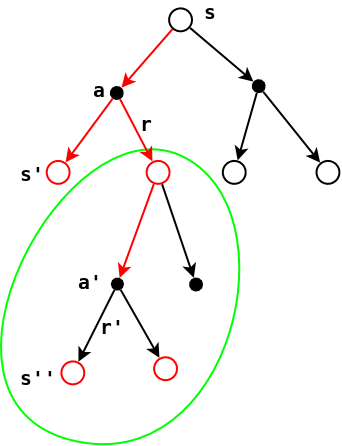
其中:
- 3-2和3-3使用了期望的加法规则。
- 3-4脱去了这个条件,因为在策略下,总是会寻找最优的动作,这和期望的下标有同样的含义,因此可以去掉这个条件。
- 3-5进一步脱掉了这个条件。从上图可以看出,在策略(寻找最优的动作)下求,无论从出发还是从出发都是一样的,因此条件期望可以进一步简化掉多余的条件,其结果不会受到影响。
- 3-6将结果合并在一起,利用了期望的期望是其本身的性质。
也就是说,对于任意的,我们总是能够找到一个策略使得其状态价值函数不小于策略下的状态价值函数,即策略,这就是policy improvement的理论依据,具体的实现就是greedy策略:对于任意的,找到使最大化的动作即为最优策略。
